 GARField
GARField
Group Anything with Radiance Fields
1 UC Berkeley 2 Luma AI
*Denotes Equal ContributionCVPR 2024


TL;DR: Hierarchical grouping in 3D by training a scale-conditioned affinity field from multi-level masks
GARField can extract assets at different granularities, like these from the above scene
Overview
Given multi-level masks from Segment Anything Model (SAM), GARField optimizes a scale-conditioned affinity field that describes how similar different 3D points are. Grouping is a fundamentally ambiguous task, where input 2D masks may be overlapping or conflicting within and across views. GARField resolves these ambiguities by conditioning on euclidean scene scale, where it selects different groupings depending on their 3D size. Once trained, GARField can be either interactively queried by providing points along with a scale, or produce globally consistent clusterings automatically at a hierarchy of scales. The groups can be used for downstream tasks like extraction or scene manipulation.
Click the thumbnails below to load scenes, see groupings at different scales.
Interactive Selection
Given a single 3D point, GARField can select multiple groups by thresholding affinity across scale!
Automatic Decomposition
GARField's affinity can be recursively clustered to break a scene into smaller and smaller subcomponents automatically.

Asset Extraction
GARField can be used to extract 3D-complete assets from casual scene scans, which can then be simulated; for example:
dropping ...
or exploded!
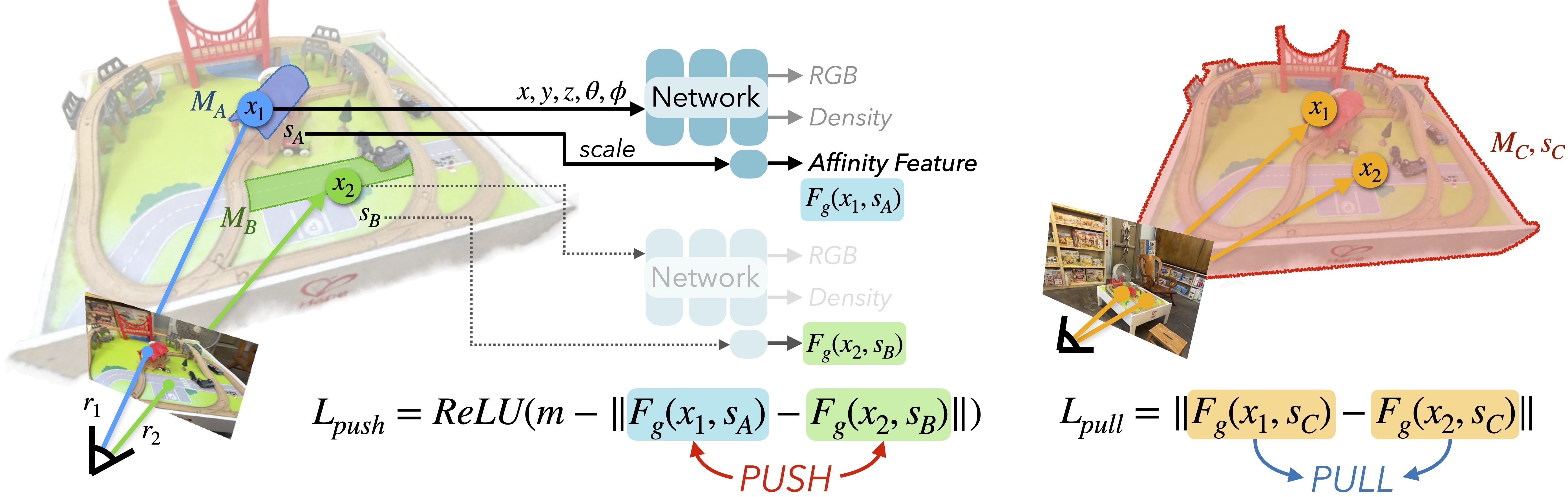
Approach: Scale-Conditioned Affinity Field Training
GARField uses a contrastive loss to optimize its feature field. Given pairs of rays in a training batch, rays which land in different 2D masks are pushed apart in feature space, and those within the same 2D mask are pulled together. Affinity is the L2 distance in feature space between points. Features are conditioned on scale, which depends on the actual 3D size of the masks obtained via backprojection.
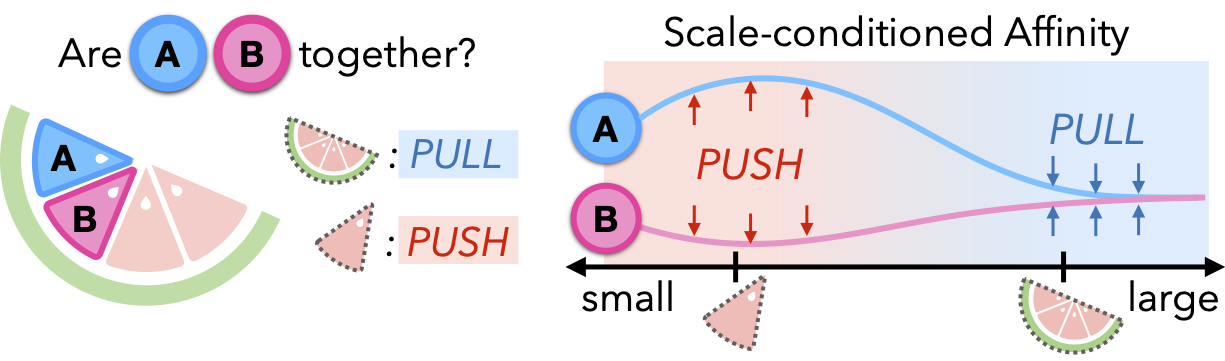
Importance of scale
Humans can interpret a scene at multiple levels of granularity. However, this richness also creates ambiguities in grouping, making it difficult to use them as supervision: Two pieces of a watermelon wedges are separate, but also part of the same watermelon. To reconcile these conflicting signals into a single affinity field, GARField embraces this ambiguity through physical scale, allowing a point to belong to different groups of different sizes.
Why Multi-View?
SAM is a 2D approach and therefore the groupings suggested by it are not 3D consistent across viewpoints and scale by definition. It also only allows for 3 possible groupings per point. GARField produces more complete groups by incorporating masks from many different views.

Citation
If you use this work or find it helpful, please consider citing: (bibtex)
@inproceedings{garfield2024,
author = {Kim, Chung Min* and Wu, Mingxuan* and Kerr, Justin* and Tancik, Matthew and Goldberg, Ken and Kanazawa, Angjoo},
title = {GARField: Group Anything with Radiance Fields},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024},
}